Anthropic has released Claude Opus 4.7, its latest flagship model, positioning it as a meaningful step forward in software engineering capabilities while maintaining a more measured approach to high-risk features such as advanced cybersecurity.
The model improves on its predecessor, Opus 4.6, particularly in handling complex, long-running coding tasks that previously required close human supervision. Early users report greater confidence in handing off difficult work, with the model showing stronger instruction following, more consistent reasoning, and a tendency to verify its own outputs before completing a task. It also brings noticeable gains in vision, now supporting higher-resolution images up to roughly 3.75 megapixels — more than three times the limit of earlier Claude versions. This opens practical applications in areas like detailed screenshot analysis, diagram extraction, and pixel-precise visual work.
Benchmarks shared by Anthropic show Opus 4.7 outperforming Opus 4.6 across several evaluations, including coding, finance agent tasks, document reasoning, and economically valuable knowledge work. The model is described as more “tasteful and creative” when producing professional materials such as interfaces, slides, and documents. It also demonstrates better use of file-system memory, allowing it to retain context across extended sessions with less need for repeated background information.
On the safety side, Anthropic has taken a deliberately cautious path with cyber-related abilities. While a more powerful Mythos Preview model exists in limited testing, Opus 4.7 was developed with efforts to moderate its cybersecurity capabilities. The release includes automatic safeguards that detect and block requests indicating prohibited or high-risk cyber uses. Security professionals interested in legitimate applications — vulnerability research, penetration testing, or red-teaming — can apply to a new Cyber Verification Program. This tiered strategy reflects the company’s broader stance on responsible scaling, prioritizing real-world testing and safeguards before wider deployment of its most capable systems.
Pricing remains unchanged from Opus 4.6 at $5 per million input tokens and $25 per million output tokens. The model is available immediately across Claude products, the API, and through partners including Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry.
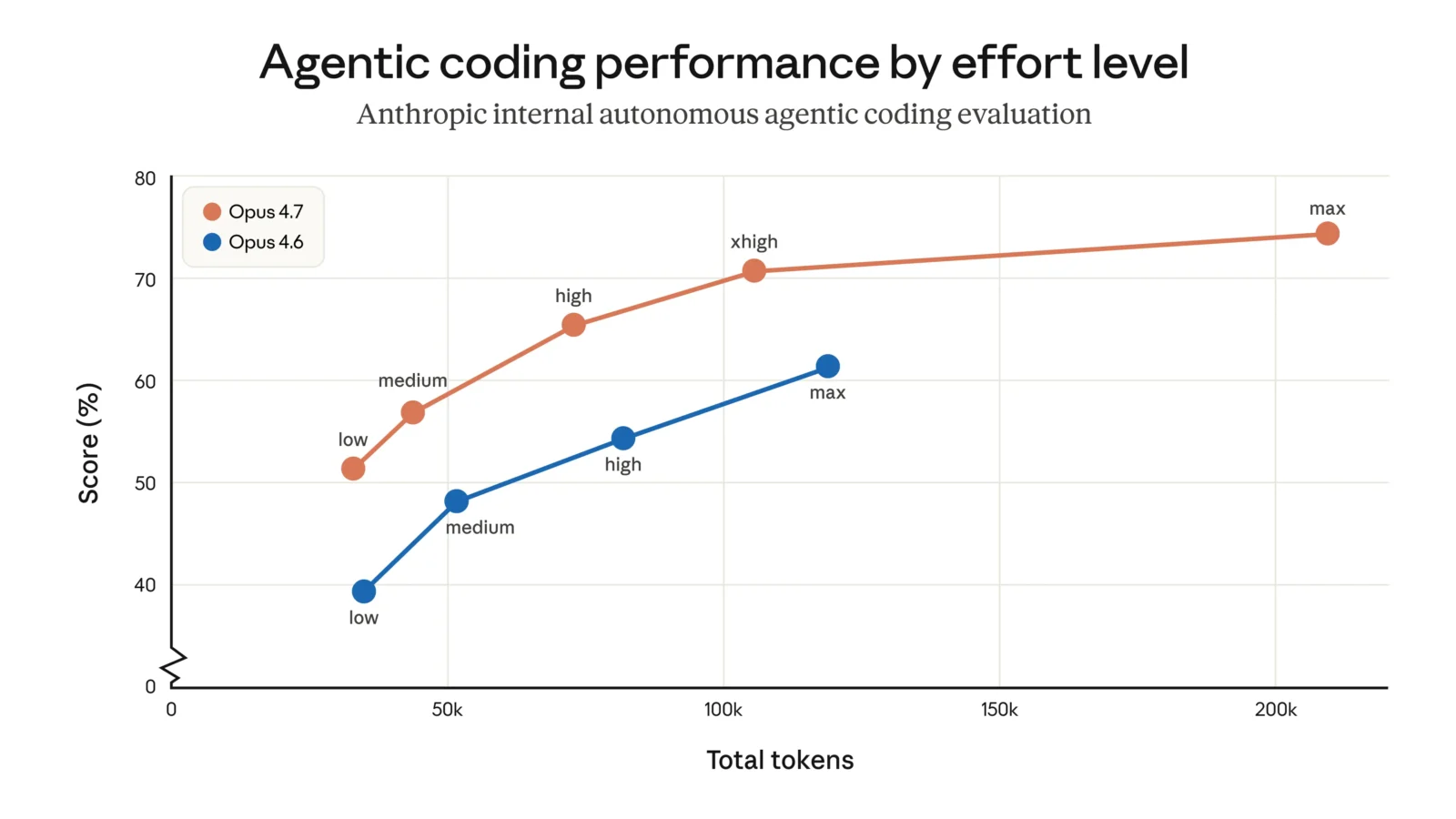
Several smaller but practical updates accompany the launch. A new “xhigh” effort level sits between high and maximum, offering finer control over the balance between reasoning depth and speed. In Claude Code, the default effort for coding tasks has been raised, and a new /ultrareview command provides dedicated code-review sessions. Auto mode, which allows the model to make certain decisions with fewer interruptions, has been extended to Max users.
Migration from Opus 4.6 is mostly straightforward, though users should note two changes that can affect token usage. The updated tokenizer sometimes maps the same text to more tokens, and higher effort levels tend to produce longer outputs, especially in agentic workflows. Anthropic provides a migration guide and recommends testing real workloads, as the net efficiency on internal coding evaluations still showed improvement.
Opus 4.7 arrives at a moment when frontier AI models are being judged not only on raw capability but on reliability, controllability, and safety trade-offs. While it does not match the broadest power of Anthropic’s Mythos Preview, the new model appears to deliver more dependable performance on demanding professional tasks without dramatically expanding the risk surface in sensitive domains. For developers and enterprises already working with Claude, it represents a solid incremental upgrade rather than a revolutionary leap, but one that may reduce the supervision burden on some of the hardest parts of software engineering and multimodal work.